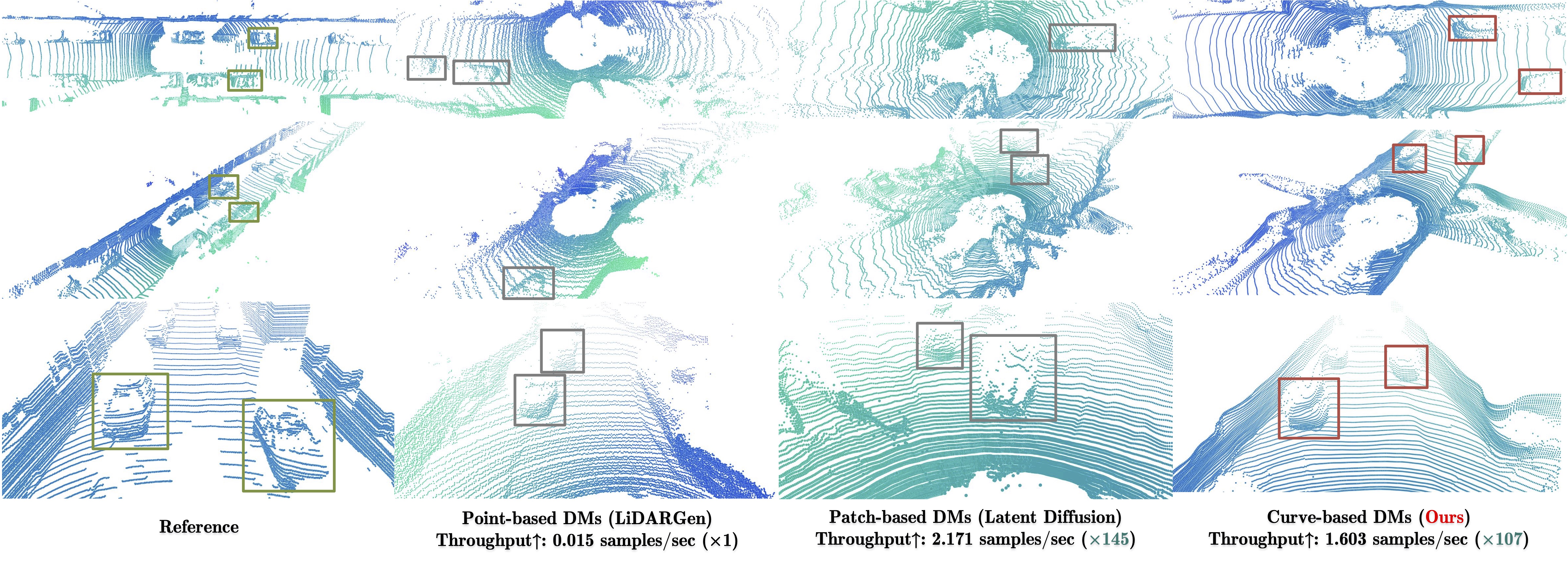
| Reference | LiDARGen | Latent Diffusion | LiDAR Diffusion |
|---|

| Reference | LiDARGen | Latent Diffusion | LiDAR Diffusion |
|---|

| Reference | LiDARGen | Latent Diffusion | LiDAR Diffusion |
|---|

| Reference | LiDARGen | Latent Diffusion | LiDAR Diffusion |
|---|
LiDAR Diffusion allows image-based conditioning with concatenation operation (e.g., semantic maps).
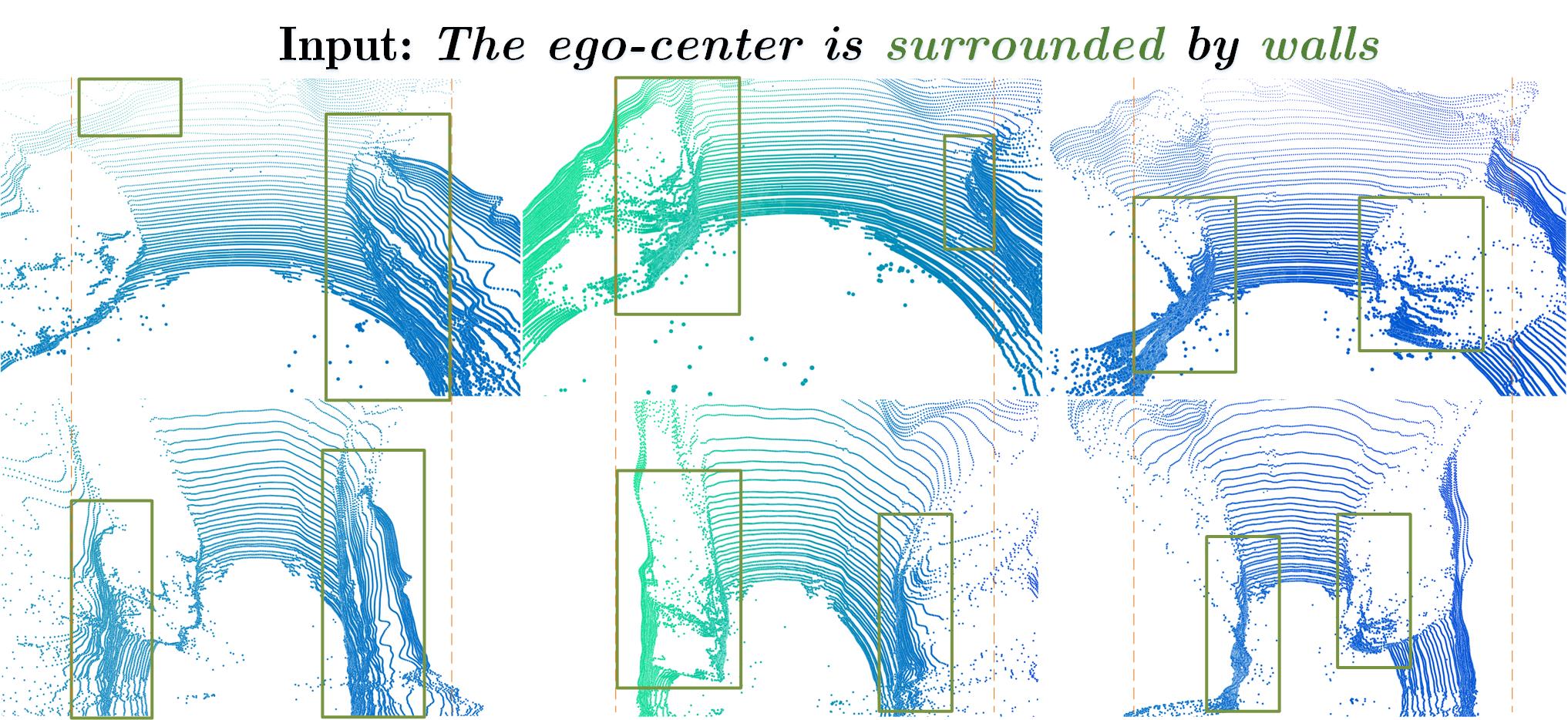
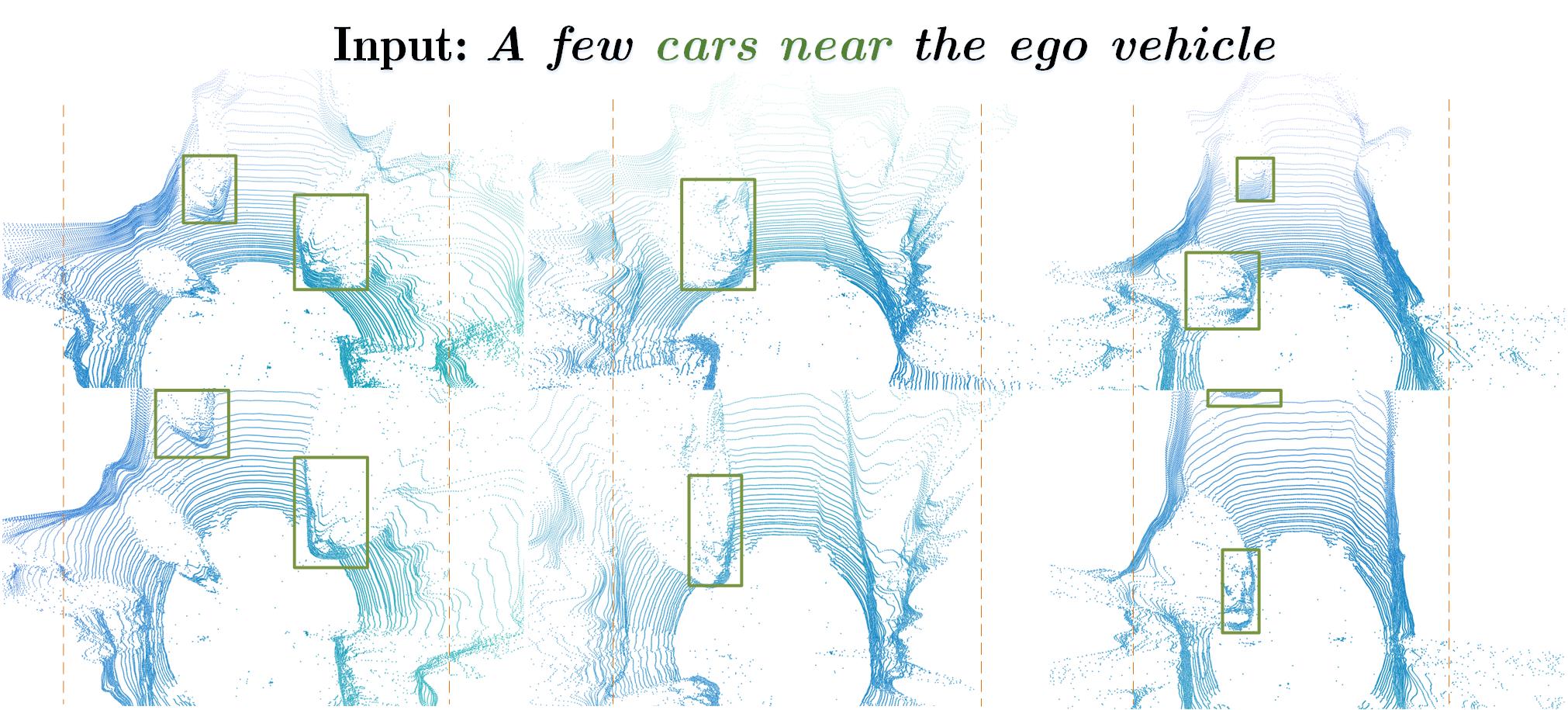
LiDAR Diffusion accepts token-based conditioning through cross-attention mechanism.

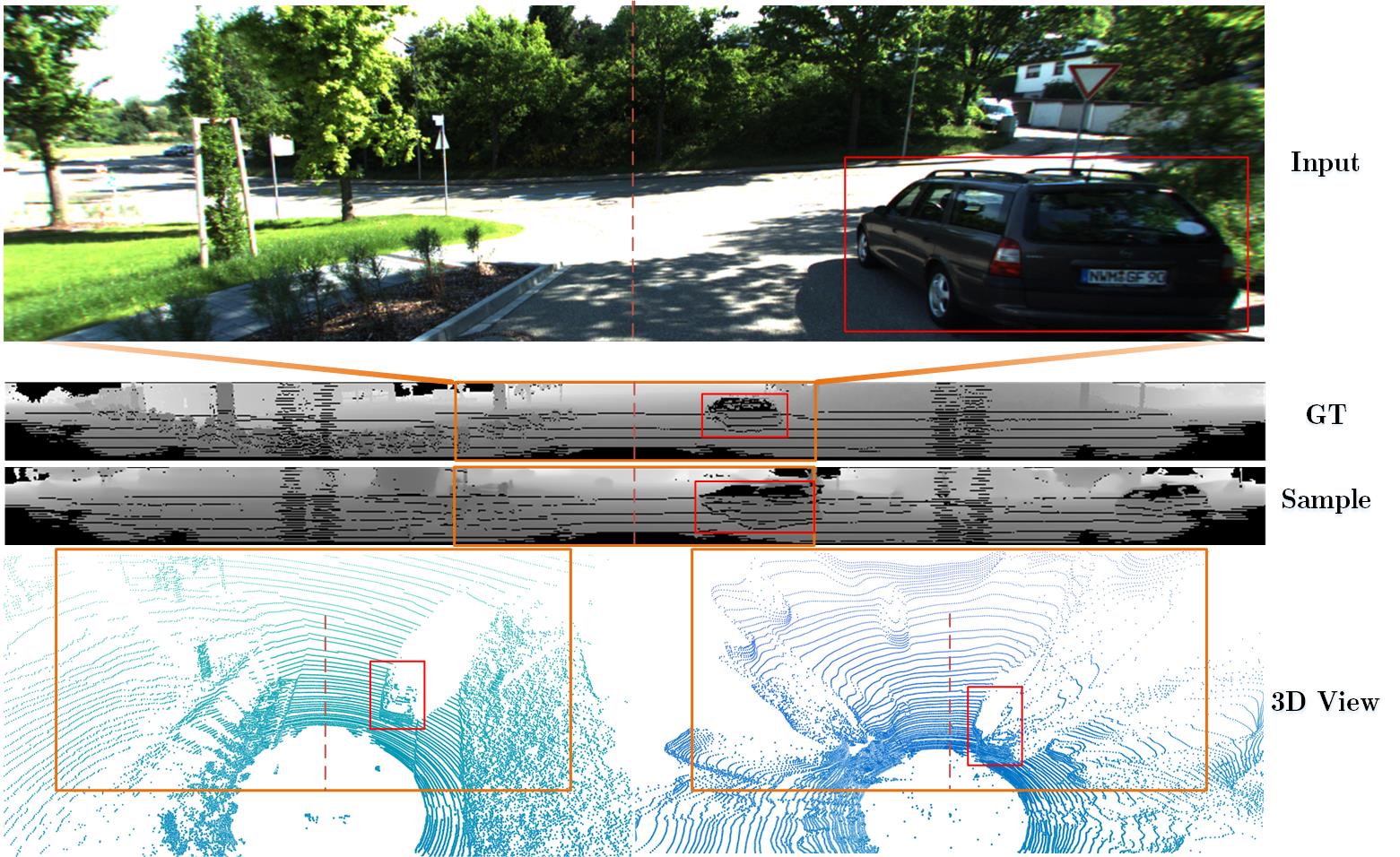
LiDAR Diffusion can be controlled by text with a pretrained CLIP-based Camera-to-LiDAR LiDM.

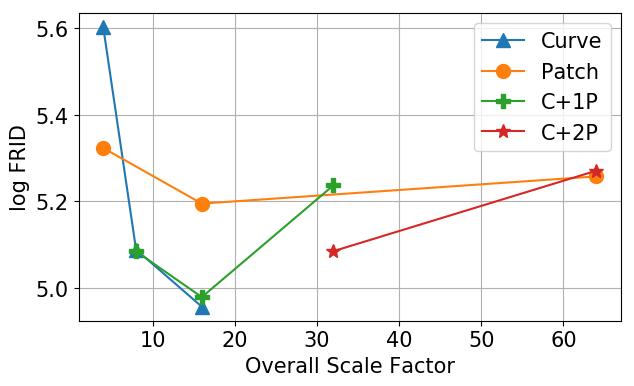
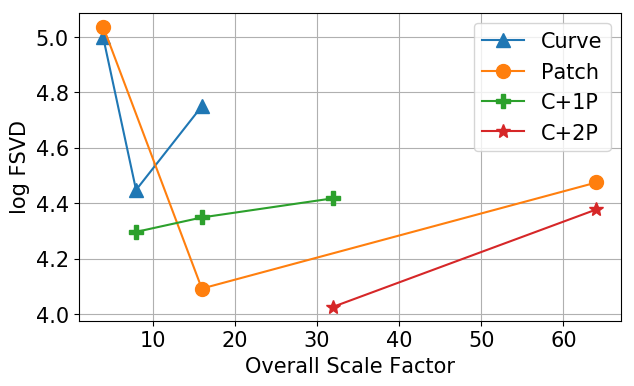
Perceptual Metrics: Fréchet Range Image Distance (FRID), Fréchet Sparse Volume Distance (FSVD). Through a comprehensive study, we demonstrate both effectiveness and efficiency of Hybrid (Curvewise+Patchwise) Encoding for LiDAR Compression.
Diffusion models (DMs) excel in photo-realistic image synthesis, but their adaptation to LiDAR scene generation poses a substantial hurdle. This is primarily because DMs operating in the point space struggle to preserve the curve-like patterns and 3D geometry of LiDAR scenes, which consumes much of their representation power. In this paper, we propose LiDAR Diffusion Models (LiDMs) to generate LiDAR-realistic scenes from a latent space tailored to capture the realism of LiDAR scenes by incorporating geometric priors into the learning pipeline. Our method targets three major desiderata: pattern realism, geometry realism, and object realism. Specifically, we introduce curve-wise compression to simulate real-world LiDAR patterns, point-wise coordinate supervision to learn scene geometry, and patch-wise encoding for a full 3D object context. With these three core designs, our method achieves competitive performance on unconditional LiDAR generation in 64-beam scenario and state of the art on conditional LiDAR generation, while maintaining high efficiency compared to point-based DMs (up to 107x faster). Furthermore, by compressing LiDAR scenes into a latent space, we enable the controllability of DMs with various conditions such as semantic maps, camera views, and text prompts.
@inproceedings{ran2024towards,
title={Towards Realistic Scene Generation with LiDAR Diffusion Models},
author={Ran, Haoxi and Guizilini, Vitor and Wang, Yue},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}